먼저 중요한 두 단어 Charset 과 Collation 의 뜻
charset 은 문자 집합, collation 은 정렬을 뜻한다.
UTF-8 이란?
실생활의 대부분의 데이터는 텍스트기반(text-centric)이다.
당연히 실생활의 모든 텍스트 데이터를 저장할 수 있는 자료형이 필요로 하게 되었다.
이것을 위해서 나온 charset이 UTF-8 이다.
UTF-8 문자 집합은 1~4 바이트까지 저장이 가능하게 설계되었다. (가변 바이트)
관련 자세한 자료는 라엘이가 쓴 글인 https://blog.lael.be/post/77 을 참고하기 바란다.
MySQL/MariaDB 에서도 UTF-8 을 지원한다.
이때! 간과한 사실이 있는데, 전세계 모든 언어가 21bit (3바이트가 조금 안됨)에 저장되기 때문에
MYSQL 에서 utf8 을 3바이트 가변 자료형으로 설계하였다.
그렇기 때문에 최근에 나온 4바이트 문자열(Emoji 같은것)을 utf8 에 저장하면 값이 손실되는 현상이 발생한다!
기존에 널리 사용되던 MySQL 구축(설계)에서 환경이, charset 은 utf8 , collation 은 utf8_general_ci 인데 이러한 대부분의 환경에서 문제를 일으키는 것이다.
4바이트 UTF-8 문자열
MySQL에서 부랴부랴 원래의 설계대로 가변-4바이트 UTF-8 문자열을 저장할 수 있는 자료형을 추가했다.
2010년 3월 24일에 utf8mb4 라는 charset을 추가하였다. (MYSQL 5.5.3 에 추가됨)
(관련 : https://dev.mysql.com/doc/relnotes/mysql/5.5/en/news-5-5-3.html )

> 한글 해석 : utf8mb4 가 추가되었습니다. 이것은 utf8 과 비슷하지만 확장된 문자를 지원하기 위해서 4바이트까지 저장할 수 있습니다.
더 자세한 이론을 원하면 Wikipedia 의 Plane 항목을 읽어보길 바란다.
(어려움. 그냥 쓰윽 읽어보세요. http://en.wikipedia.org/wiki/Plane_(Unicode) )
대충 이런 뜻이다.
- utf8 : Basic Plane.
- utf8mb4 : Basic Plane + Supplementary Plane.
그리고 중요한 것!!! Emoji 문자열이 모두 4 Byte 이다!!
요즘 스마트폰에서 이미 있는 문자이고, 라엘이의 경우 운영체제로 Mac OS X 를 사용하는데,
Mac 에서 커멘드+컨트롤+스페이스를 입력하면 나오는 키보드이다.
-- 참고 이미지 --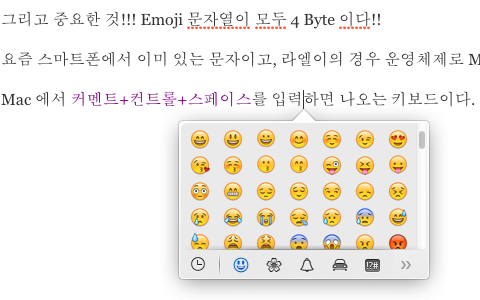
-- 참고 이미지 --
즉 이러한 SMP (Supplementary Multilingual Plane) 를 처리하기 위해서
당신의 DBMS 가 utf8mb4 를 지원한다면 반드시 이것으로 지정하길 바란다.
Collation (정렬 방식).
latin1 (2바이트), utf8 (가변3바이트), utf8mb4 (가변4바이트)는 저장공간의 크기이다.
위의 것들은 charset 이라고 부른다.
(웹)프로그램과 데이터베이스가 문자를 주고 받을 때는 charset 만 설정하면 된다.
“내가 보낼 문자열은 utf8mb4 에요!” 라고 알려주고 text stream 을 전송하면 알맞게 처리하기 때문이다.
Collation 은 텍스트 데이터를 정렬(ORDER BY)할 때 사용한다. 즉 text 계열 자료형에서만 사용할 수 있는 속성이다.
int 형 : 1500 < 1700 으로 명확하다.
date 형 : 2013-10-20 < 2015-12-20 으로 명확하다.
- 그렇다면 text 형 :
a 와 b 중 어느 것이 더 큰가?
a 와 A 중 어느 것이 더 큰가?
a 와 á 중 어느 것이 더 큰가?
- 주로 많이 사용하는 collation 3가지 비교.
ORDER BY `text` ASC* utf8_bin (or utf8mb4_bin)
바이너리 저장 값 그대로 정렬한다.
hex 코드(16진수)로 A 는 41, B 는 42, a 는 61, b 는 62 이기 때문에 다음 순서로 출력된다.

* utf8_general_ci (or utf8mb4_general_ci)
텍스트 정렬할 때 a 다음에 b 가 나타나야 한다는 생각으로 나온 정렬방식. 일반적으로 널리 사용된다.
라틴계열 문자를 사람의 인식에 맞게 정렬한다.
바이너리를 한번 가공한 것이다.

* utf8_unicode_ci (or utf8mb4_unicode_ci)
general_ci 보다 조금 더 사람에 맞게 정렬한다.
한국어, 영어, 중국어, 일본어 사용환경에서는 general_ci 와 unicode_ci 의 결과가 동일하다.
뭔가 더 특수한 문자의 정렬 순서가 변경된다. 다음의 스크린샷을 참조하여라.
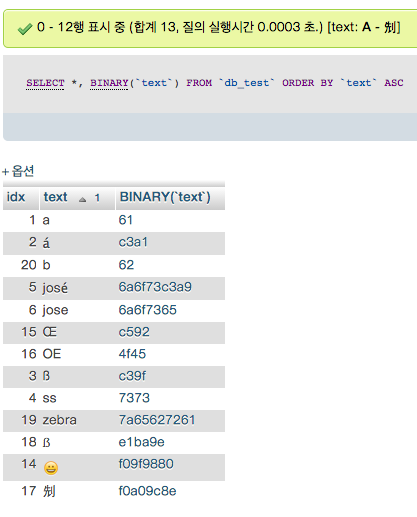
<위의 예시는 상당히 많은 의미를 가지고 있다. 자세히 살펴보도록 하자.>
다음은 권장하는 charset 과 collation 설정 값이다.
1) MySQL 5.5.3 이전 = utf8 charset 에, utf8_general_ci collation 사용.
2) MySQL 이 최신일 때 = utf8mb4 charset 에, utf8mb4_unicode_ci collation 사용.
요약 : 이 문제는 MYSQL / MariaDB 에서만 일어납니다.
1) 다국어를 처리할 수 있는 UTF-8 이라는 저장방식이 있음. 원래 설계는 가변4바이트임.
2) 전세계 모든 언어문자를 다 카운트 해봤는데 3 바이트가 안됨.
3) MYSQL/MariaDB 에서는 공간절약+속도향상 을 위해서 utf8 을 가변3바이트로 설계함.
4) Emoji 같은 새로나온 문자가 UTF-8의 남은 영역을 사용하려함 (4바이트 영역).
5) MYSQL/MariaDB 에서 가변4바이트 자료형인 utf8mb4 를 추가함. (2010년 3월에).
기존 utf8 시스템을 utf8mb4 로 바꾸어도 값의 손실은 없습니다.
Emoji 문자열의 저장을 지원하지 않으려면 굳이 utf8mb4 를 사용하지 않아도 됩니다. (이 경우 데이터베이스에 텍스트 값 저장 전에 필터링을 하기 바랍니다.)
예시 my.ini
------------------------------------------------------------------------------------------------------------------------------
[mysqld]
basedir=C:/Program Files/MariaDB 10.1
datadir=C:/Program Files/MariaDB 10.1/data
port=3306
sql_mode="STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION"
default_storage_engine=innodb
innodb_buffer_pool_size=2031M
innodb_log_file_size=50M
collation-server = utf8mb4_unicode_ci
character-set-server = utf8mb4
skip-character-set-client-handshake
[client]
default-character-set = utf8mb4
port=3306
-----------------------------------------------------------------------------------------------
collation-server, character-set-server, default-character-set 설정값이 틀릴시 mysql 실행이 안됨
예기치 않은 오류 발생
참고 https://blog.lael.be/post/917
'DataBase > MySQL' 카테고리의 다른 글
| [MySQL] 1449 ERROR - The user specified as a definer (0) | 2016.04.12 |
|---|---|
| [MYSQL] duplicate INSERT (0) | 2016.03.25 |
| [MySQL] TIMEZONE 설정 (0) | 2016.03.07 |
| [CentOS] mysql, maria DB sql 파일 import (0) | 2016.02.29 |
| CentOS 7 mariaDB (0) | 2016.02.29 |